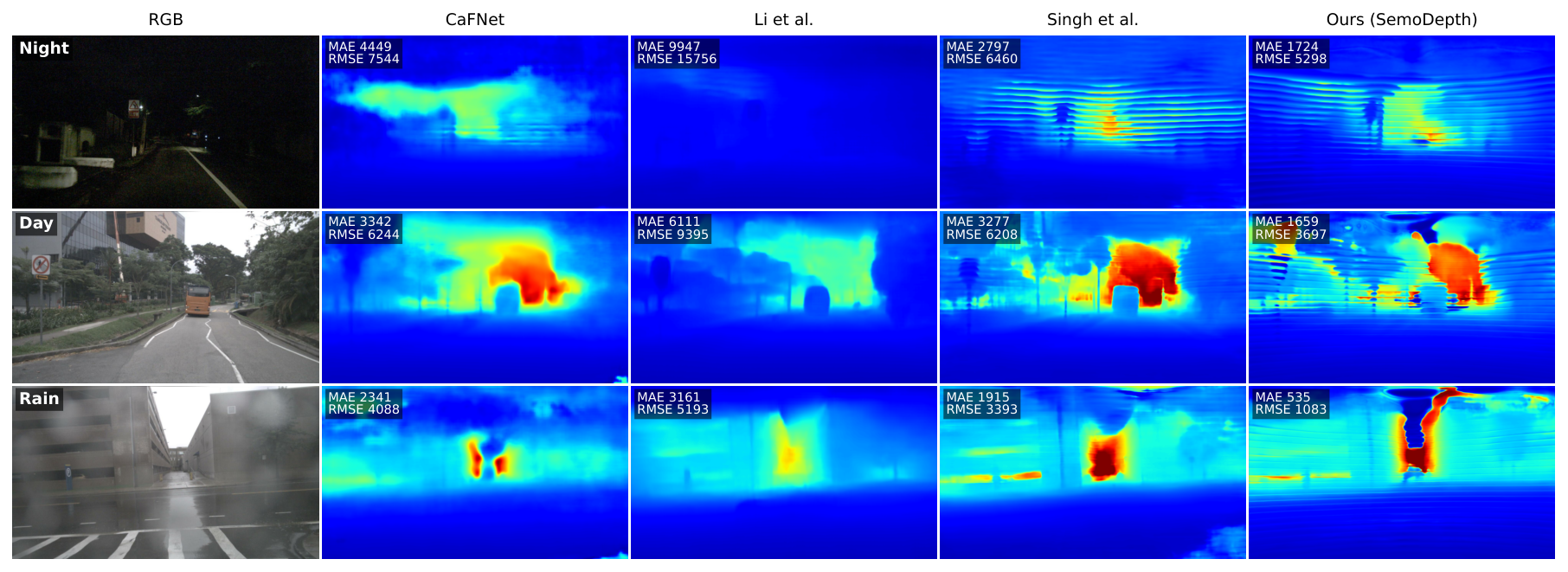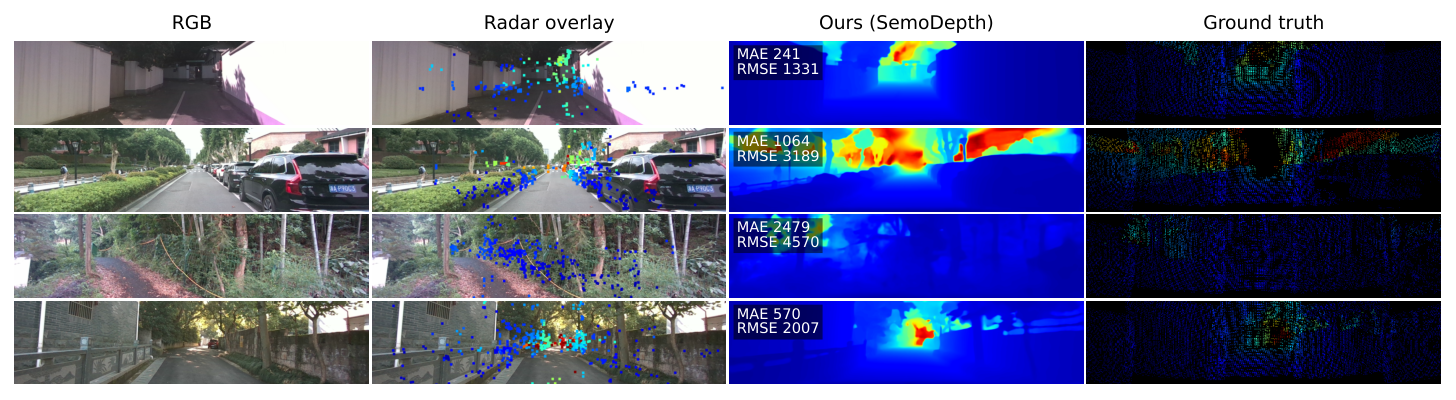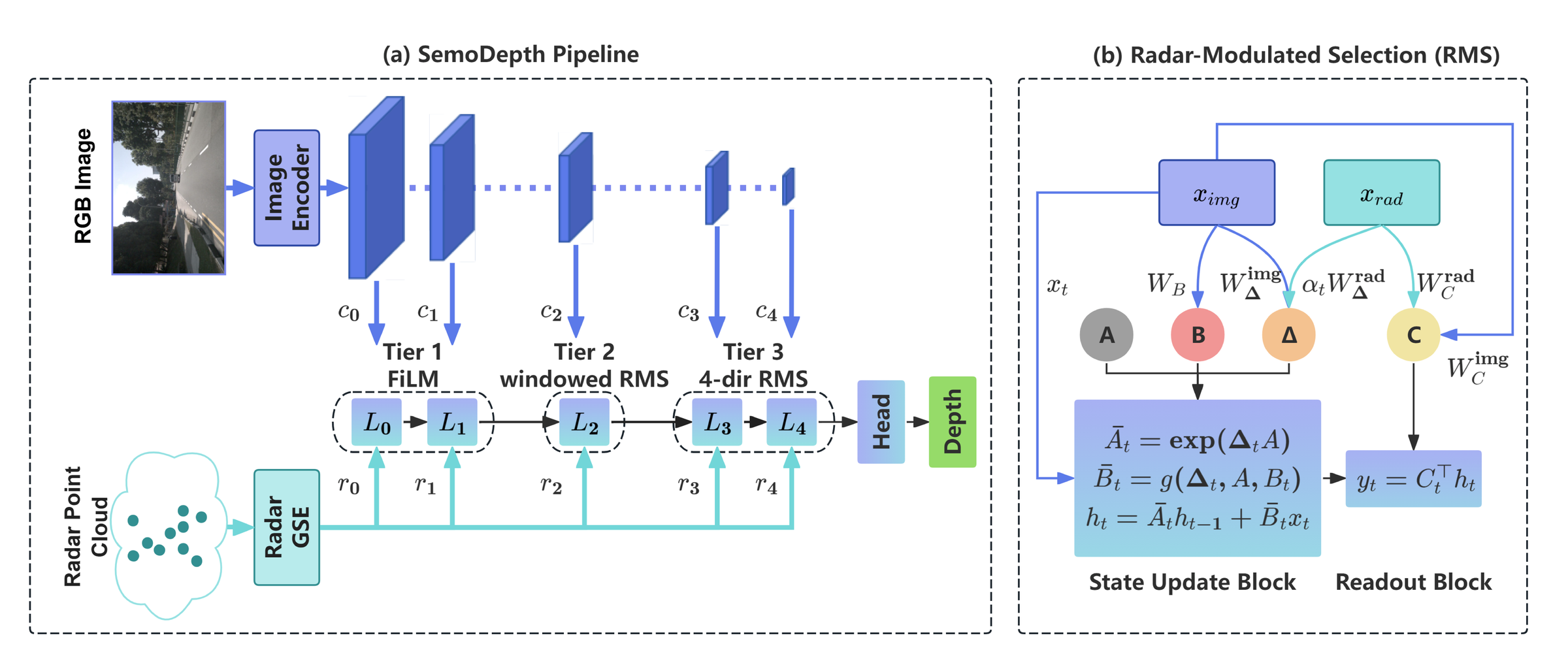
SemoDepth overview. (a) Pipeline. A ResNet-34 image encoder and a PCA-GM radar GSE produce the image pyramid $c_0,\dots,c_4$ and a single radar feature map whose level-wise projections form the radar pyramid $r_0,\dots,r_4$. The Multi-View Scan Pyramid (MVSP) allocates fusion by resolution: FiLM modulation at the finest levels (Tier 1), radar-centred windowed RMS at the mid level (Tier 2), and full-image four-direction RMS at the coarsest levels (Tier 3). (b) Radar-Modulated Selection (RMS). Radar enters via additive modulations to the step size $\boldsymbol{\Delta}_t$ and readout $\mathbf{C}_t$ (dashed red), while the input projection $\mathbf{B}_t$ and state-evolution matrix $\mathbf{A}$ remain image-only (blue). All radar projections are zero-initialised, so at step 0 the block is bit-equivalent to vanilla Mamba.